Activation Functions in Neural Networks: Types, Applications, and Examples in PyTorch and TensorFlow

Joseph Ngunjiri
An activation function in a neural network is a mathematical function that calculates the output of a node based on its individual inputs and their weights, introducing non-linearity to enable the network to model complex patterns and relationships. It determines the output of the neural network, such as yes or no, by converting the values to a range like {0 to 1} or {-1 to 1}, depending on the specific function used. That sounds intricate? Don't worry; in this article we'll break down the concept, discuss different types of activation functions and their roles in neural networks. We will evaluate activation functions like ReLU, Tanh, SELU, linear, and ELU and know when to choose a specific activation function in your projects. These functions are grouped into two types, linear and nonlinear. Linear activation functions are limited to regression to ensure the output is a numerical value. All other functions utilize non-linear functions. This article will therefore focus on non-linear activation functions. If you understand parameters, neurons, and layers, you can jump to the section What Activation Functions do in a Neural Network.
Here are some terms that will be frequently used in the article:
Weight: It's like the constant m in a linear equation y = mx + c. The constant, which is initially a random number, can be adjusted during training to provide more accurate predictions.
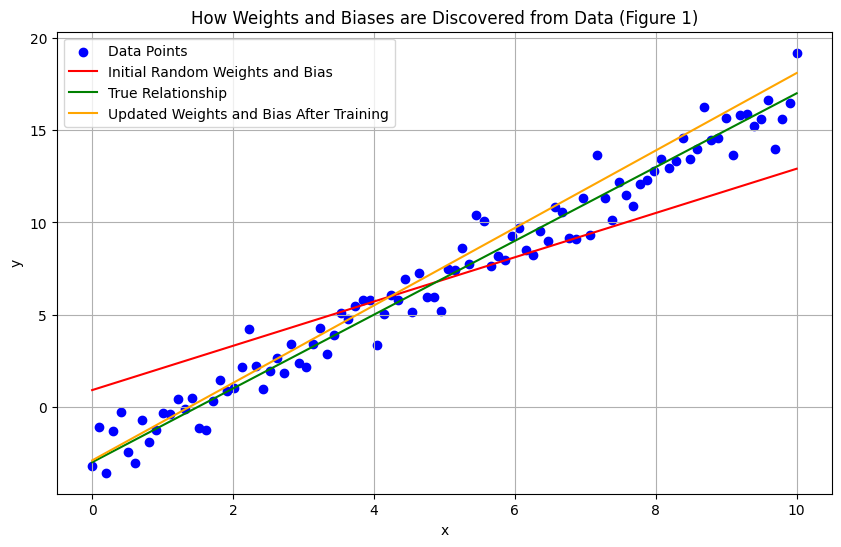
Bias: A parameter/value included in a model to compensate for inherent inaccuracies or inconsistencies between the model's predictions and the observed data. For example, there may be a linear relationship between 2 variables, x and y. When you plot them on a graph, they do not pass through the origin (point {0,0} on an x-y plot).
If they go above the origin, you add a value to the relationship between the two values to get the equation for it.
If they go below the origin, you subtract a value from the relationship between the two values to get the equation for it.
The value that we are adding or subtracting to get the correct relationship is the bias. In the equation y = mx + c, c is the bias. Figure 1 below elaborates how bias and weights come up in functions.
Node: Nodes, artificial neurons, and neurons are terms used interchangeably. Neural networks and artificial intelligence, in general, are concepts inspired by how the brain works to help us process information. Brain cells (neurons) send electric signals to each other to communicate and process information, which allows us to think, learn, and make decisions. Similarly, in artificial neural networks, artificial neurons communicate and process data to perform tasks like classification, prediction, and pattern recognition.
Layer: Each node takes in data, and passes some output to the next node. A set of nodes set to achieve a single goal is called a layer. Neural networks have 3 types of layers; input layer, hidden layer(s) (hidden to effect the real magic of a network 😊), output layer. There is mostly more than one hidden layer in a neural network.
Figure 1: How Weights and Biases are Discovered from Data
To get the most out of this tutorial, you should know the basics of Python and neural networks.
This is the 10th time I'm saying "neural network." To keep it simple, let's just call it NN.
What Activation Functions do in a Neural NetworkWhat Activation Functions do in a Neural Network
A neural network needs features (data) with labels to learn. Labels are the correct outputs from the provided data.
In the equation 2 + 4 + 5 = 11, the numbers 2, 4, and 5 are the features/ data, and the number 11 is the label.
In a dataset where we have characteristics of a house and its environment, and corresponding price for each house, characteristics are the features and price is the label.
In a neural network, such data undergoes a sequential transformation as it flows through its layers. Each layer receives input data, processes it to produce output, and then forwards that output to the next layer.
Throughout this process, the nodes within each layer utilize weights and biases to modify the incoming inputs.
Additionally, an activation function is applied to the transformed output of each node, introducing non-linearity and allowing the network to capture complex patterns and relationships in the data.
The cycle continues until the final layer produces a prediction, which is then compared to the actual labeled output to adjust the weights and biases, minimizing the prediction error.
Complex patterns and relationships in data are mostly non-linear. Since neural network models without activation functions are limited to linear transformations, they struggle to predict non-linear patterns.
A simple linear regression equation is sufficient to model the relationship between length of a metal bar and temperature. The linear regression equation is the neural network model in this case.
House price can be predicted based on data like street name, county, number of rooms, number of bathrooms, square footage, age, architectural style, availability of nearby amenities.
A linear regression equation may not capture the trend in this case. A nonlinear function can do it efficiently. The non-linearity factor in the function is introduced by an activation function.
With that in mind, we can now explore specific cases of the activation functions in action.
Examining Common Activation Functions
1. Sigmoid Activation Function
The probability of any event always falls between 0 and 1. Activation functions help keep outputs within this range, typically between 0 and 1 or -1 and 1.
The sigmoid function can handle all real numbers as input, from negative infinity to positive infinity.
The Sigmoid function's output range matches the probability range of {0, 1}. The function is also S-shaped and non-linear.
These properties make sigmoid function very useful in transforming linear outputs into non-linear responses. Models that predict probabilities e.g. binary classifications, utilize the power of sigmoid activation function.
Figure 2: Illustration of Sigmoid activation function
Gradient-based optimization techniques such as backpropagation benefit from this activation function.
2. Tanh Activation Function
The tanh activation function is used in neural networks to transform input values into outputs between -1 and 1. It's also called the hyperbolic tangent activation function. This transformation is helpful for the learning process.
The function looks like an S-shaped curve centered around zero, which means that inputs close to zero stay close to zero, and extreme inputs (very positive or very negative) get squished towards -1 or 1.
Figure 3: Illustration of tanh activation function
Using tanh can make the training of a neural network faster because it helps balance the outputs and gradients.
However, for very large or very small inputs, the gradient (or change) becomes very small, which can slow down the training of deeper networks.
3. ReLU (Rectified Linear Unit) Activation Function
ReLU (Rectified Linear Unit) is an activation function used in neural networks, defined as:
It outputs the input directly if positive, and zero otherwise, introducing non-linearity to the model while being computationally efficient.
Figure 4: Illustration of ReLU activation function
ReLU mitigates the vanishing gradient problem, allowing for faster training and improved performance in deep networks.
However, it can suffer from the "dying ReLU" problem where neurons become inactive and only output zero.
Variants like Leaky ReLU address this issue by allowing a small, non-zero gradient when the input is negative.
ReLU's simplicity and effectiveness make it popular in deep learning.
4. Softmax Activation Function
The softmax activation function is used in machine learning, especially for classification tasks.
It takes a vector of real-valued scores (logits) and converts them into probabilities.
Each score is exponentiated and then divided by the sum of all exponentiated scores, ensuring the output values range between 0 and 1 and sum to 1.
Here's a simple example where we have three classes with scores [2, 1, 0.1]. Applying softmax:
Exponentiate each score: [e^2, e^1, e^0.1] = [7.39, 2.72, 1.11].
Sum these values: 7.39 + 2.72 + 1.11 = 11.22.
Divide each exponentiated score by this sum: [7.39/11.22, 2.72/11.22, 1.11/11.22] ≈ [0.66, 0.24, 0.10].
Figure 5: Illustration of Softmax activation function
These probabilities indicate the model's confidence in each class, with the highest score being the most likely.
The softmax activation function is widely applied in the output layer of neural networks for multi-class classification problems. It's particularly used in applications like image classification, natural language processing, and voice recognition.
For instance, in image classification, a model might be trained to recognize whether an image is of a cat, dog, or bird. Softmax converts the raw output scores into probabilities for each class, making it easy to interpret and decide which class the image most likely belongs to.
This probabilistic output is essential for tasks where a single instance can belong to multiple possible categories.
Moreover, during training, the softmax output is used with a cross-entropy loss function to effectively penalize the differences between the predicted and actual class probabilities, thereby optimizing the model's accuracy.
5. Other Activation Functions
Besides Sigmoid, Tanh, ReLU, and softmax activation functions, there are other activation functions like Leaky ReLU, PReLU, ELU, and Swish.
Leaky ReLU: Unlike ReLU, which outputs zero for negative inputs, Leaky ReLU allows a small, non-zero gradient (a small negative slope). This helps prevent neurons from "dying" during training.
PReLU (Parametric ReLU): A variation of Leaky ReLU where the negative slope is learned during training. This adaptability can improve model performance.
ELU (Exponential Linear Unit): ELU outputs a small negative value for negative inputs and smooths the transition from negative to positive, which can speed up training and lead to better performance.
Swish: Its a smooth, non-monotonic function. Swish can improve performance on deeper networks due to its smooth gradient flow.
These functions are beneficial in scenarios like deep networks or when dealing with dying neurons, enhancing model convergence and performance.
6. Choosing the Right Activation Function
Choosing the right activation function depends on the task and network depth. For regression, use ReLU or its variants (Leaky ReLU, PReLU) for their simplicity and efficiency.
In binary classification, Sigmoid or Tanh is common, but ReLU-based functions can also work well.
For multi-class classification, Softmax in the output layer is standard. Deep networks benefit from Swish or ELU due to better gradient flow.
Performance considerations include computational efficiency and handling vanishing/exploding gradients.
Hyperparameter tuning, like adjusting PReLU's slope, is crucial for optimizing model performance. Experimentation and validation are key to finding the best fit.
Practical Implementation of Activation FunctionsPractical Implementation of Activation Functions
1. Using Activation Functions in PyTorch
In PyTorch, implementing activation functions is straightforward using the torch.nn module.
Here's a practical example showcasing how to use common activation functions and build a sample neural network:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# Define a simple neural network class
class SimpleNN(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, activation):
super(SimpleNN, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
self.activation = activation
def forward(self, x):
x = self.activation(self.fc1(x))
x = F.softmax(self.fc2(x), dim=-1) # Softmax for multi-class classification
return x
# Example usage of different activation functions
input_dim = 10
hidden_dim = 20
output_dim = 5
# ReLU activation function
model_relu = SimpleNN(input_dim, hidden_dim, output_dim, nn.ReLU())
print("Output with ReLU activation:")
print(model_relu(torch.randn(1, input_dim))) # Sample input
# Sigmoid activation function
model_sigmoid = SimpleNN(input_dim, hidden_dim, output_dim, nn.Sigmoid())
print("\nOutput with Sigmoid activation:")
print(model_sigmoid(torch.randn(1, input_dim))) # Sample input
# Tanh activation function
model_tanh = SimpleNN(input_dim, hidden_dim, output_dim, nn.Tanh())
print("\nOutput with Tanh activation:")
print(model_tanh(torch.randn(1, input_dim))) # Sample inputIn this example, SimpleNN defines a two-layer neural network with configurable activation functions (nn.ReLU(), nn.Sigmoid(), nn.Tanh()).
Each instance of SimpleNN uses a different activation function to demonstrate their effects on the network's output.
The forward method applies the activation function after each linear layer (fc1 and fc2), followed by a softmax activation for multi-class classification in the output layer.
This approach allows for flexibility in experimenting with different activation functions based on the specific requirements of the task, such as classification or regression.
By printing the output of each model with randomly generated input, you can observe how different activation functions influence the final predictions of the neural network.
2. Using Activation Functions in TensorFlow
In TensorFlow, implementing activation functions is straightforward using its built-in layers and activations. Here’s how you can incorporate common activation functions into a neural network:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.initializers import HeNormal
# Define a neural network with different activation functions
model = Sequential([
Dense(64, kernel_initializer=HeNormal(), input_shape=(input_dim,)),
Activation('relu'), # ReLU activation
Dense(32),
Activation('sigmoid'), # Sigmoid activation
Dense(10),
Activation('softmax') # Softmax activation for multi-class classification
])
# Compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# Generate some random input data (replace with your actual data)
import numpy as np
input_data = np.random.rand(100, input_dim)
labels = np.random.randint(0, 10, size=100)
# Train the model
model.fit(input_data, labels, epochs=10, batch_size=32, validation_split=0.2)
# Evaluate the model
loss, accuracy = model.evaluate(input_data, labels)
print(f'Loss: {loss}, Accuracy: {accuracy}')This example demonstrates a neural network with three layers where each layer uses a different activation function:
The first hidden layer uses ReLU activation, suitable for improving convergence in deep networks.
The second hidden layer uses Sigmoid activation, typically used for binary classification tasks.
The output layer employs Softmax activation, which is ideal for multi-class classification as it outputs probabilities for each class.
You can replace input_dim with the appropriate number of input features for your dataset. Experiment with other activation functions like Tanh, Leaky ReLU, or custom activations as needed for your specific tasks.
This setup allows for practical implementation and experimentation with various activation functions to optimize your neural network's performance.
Troubleshooting and Best Practices while working with Activation FunctionsTroubleshooting and Best Practices while working with Activation Functions
1. Vanishing and Exploding Gradients:
In deep neural networks, gradients can diminish significantly during backpropagation, particularly with activation functions such as Sigmoid and Tanh. This can lead to slow learning or stagnation in training.
To mitigate this issue, it is recommended to use activation functions like ReLU or its variants (Leaky ReLU, PReLU, ELU), which maintain more consistent gradient magnitudes and prevent them from vanishing too quickly.
Conversely, gradients can also grow excessively large, causing instability in weight updates—a phenomenon known as exploding gradients.
To address this, techniques like gradient clipping can be applied to cap the gradient values during backpropagation.
Additionally, using proper weight initialization methods such as He initialization for ReLU activations and incorporating normalization techniques like Batch Normalization can help stabilize gradient flow and improve the overall training process.
These practices ensure more stable and efficient learning in deep neural networks.
2. Overfitting and Underfitting Related to Activation Functions:
Overfitting occurs when a model performs well on training data but poorly on validation data, indicating it has memorized noise rather than learned general patterns.
To mitigate overfitting, regularization techniques like dropout can be employed. Additionally, simpler activation functions such as ReLU can help by inherently imposing a form of regularization.
Underfitting, on the other hand, happens when a model performs poorly on both training and validation data, suggesting it lacks the capacity to capture the underlying patterns.
To address underfitting, more expressive activation functions like PReLU or Swish can be used.
These functions allow the model to represent more complex relationships and patterns in the data, potentially improving its performance on unseen data.
3. Tips for Effective Use of Activation Functions:
Effective use of activation functions involves matching them to specific tasks: ReLU-based functions are suitable for regression, while Sigmoid and Softmax are preferred for binary and multi-class classification, respectively.
In deeper networks, activation functions like ELU and Swish enhance gradient flow, aiding convergence.
Experimenting with variants such as Leaky ReLU and PReLU can prevent issues like "dying ReLU," ensuring robust performance across different network architectures and training scenarios.
4. How to Experiment and Iterate:
Begin by using standard activation functions such as ReLU and Sigmoid. Monitor both training and validation loss to catch vanishing or exploding gradients promptly. Analyze gradients and activations layer by layer to identify specific issues.
Employ techniques like Grid Search or Random Search for hyperparameter tuning, which includes adapting parameters like the negative slope in PReLU to optimize model performance effectively.
import tensorflow as tf
from tensorflow.keras.layers import Dense, Activation
from tensorflow.keras.models import Sequential
from tensorflow.keras.initializers import HeNormal
# Example: Using He initialization and ReLU
model = Sequential([
Dense(64, kernel_initializer=HeNormal(), input_shape=(input_dim,)),
Activation('relu'),
Dense(1) # Output layer for regression
])
model.compile(optimizer='adam', loss='mse')Here, we use He initialization with ReLU to mitigate vanishing/exploding gradients in a regression task. Always validate the choices with cross-validation and experiment iteratively to find the best configuration.
Conclusion
Understanding and effectively utilizing activation functions is crucial for building successful neural networks.
These functions introduce non-linearity, enabling the network to model complex patterns and relationships within data.
By exploring common activation functions like ReLU, Sigmoid, Tanh, and Softmax, and learning their specific applications, you can make informed choices to optimize your neural network's performance.
Practical implementation in frameworks like PyTorch and TensorFlow, combined with best practices for troubleshooting, ensures robust and efficient model training.
As you experiment and iterate, these insights will guide you in selecting the right activation functions for your machine learning projects.
Did you find the article helpful?